

1. Overview
1.1 What is Reactive Programming
Reactive Programming is a programming paradigm that allows programs to run in asynchronous non blocking way and support back pressure mechanism. Think of Java collections `Streams` on steroid. It is a Development model structured around building asynchronous Observable data streams.
In Reactive Programming, data streams become the spine of your application. Messages, Calls, Failures are conveyed by streams. You observe those streams and react to them when data is emitted. You will create data streams out of anything and everything. Mouse clicks, http requests, Kafka messages, cache events, changes on a variable. Along with this concept comes a set of tools that allows you to create , merge, filter, transform, and combine streams.
Spring WebFlux library is built on top of Reactor project which implements the `Mono` and `Flux` API types to work on data sequences of 0..1(Mono) and 0..N(Flux) through a rich set of operators aligning with ReactiveX operators. all Reactor operators support non-blocking back pressure.
Typical Tomcat Server with 200 threads thread pool we can server 200 concurrent requests at most other requests will get server not available error
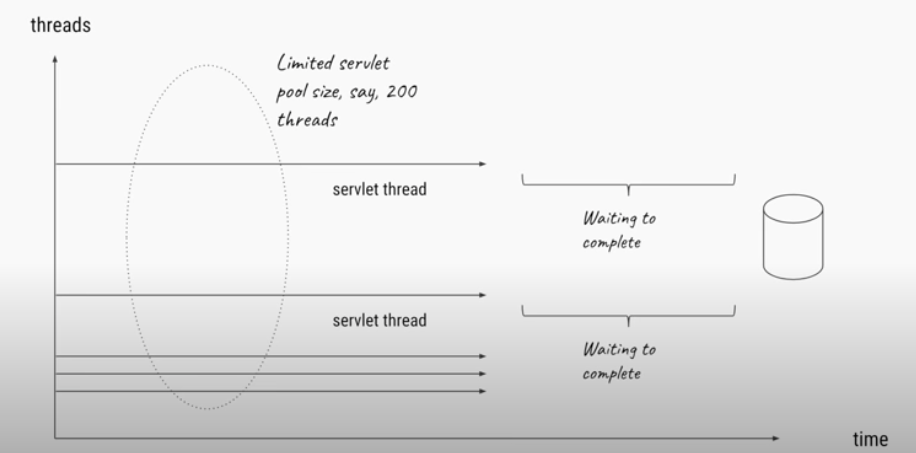
NIO Server with Thread loop, few number of threads thread is either working or free never blocking waiting on I/O
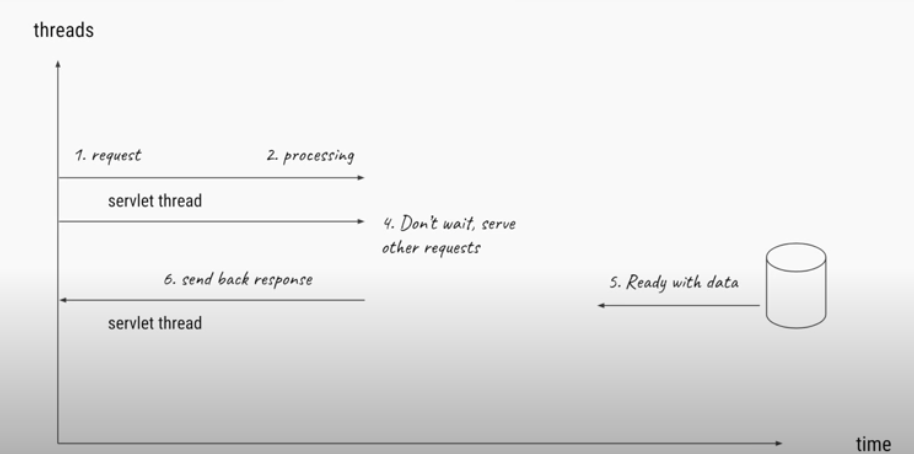
Server can now can use small number of threads but server large number of requests

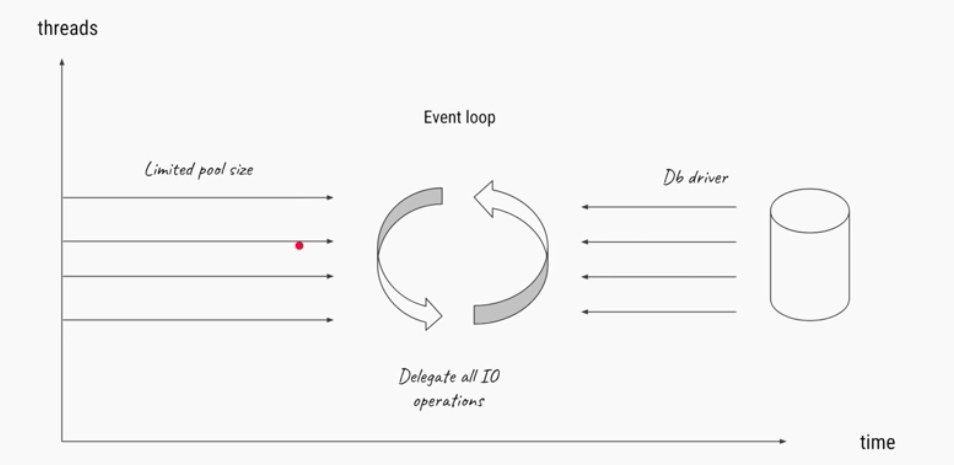
Reactive programming, goes hand in hand with functional programming style, we use callback functions that are triggered based on type of events happening in the stream. Reactive streams are built using `Observable design pattern` You can think of the stream as the Observable while the functions we define to handle events like complete, next, error are Listener or Observers to the stream. Reactive streams are built using function chaining and each stream is immutable hence any operations done in a subscribing function to a stream doesn't impact the original stream, It generates a new stream instead.
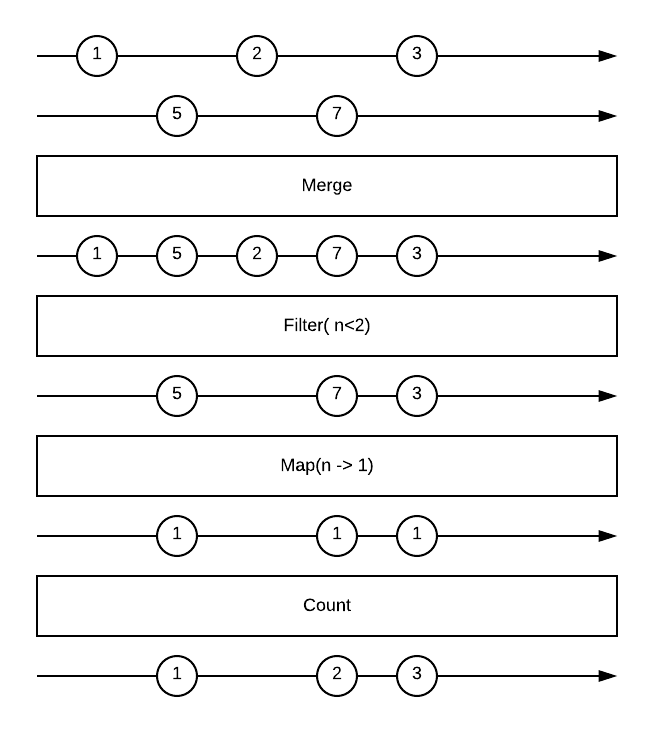
1.2 Performance
In general using reactive APIs doesn't make the application faster or more performant. It may in some cases (when making parallel calls in parallel). but the extra work required to make application asynchronous and non-blocking can add extra processing time
The key benefit of reactive and non-blocking is ability to scale with small fixed number of threads and less memory. scaling becomes more predictable. Benefits start to show when there's latency and some slow and unpredictable network I/O. Difference can be drastic
1.3 Concurrency
To scale and use limited number of threads may sound contradictory. But when threads don't block and rely on call backs instead there's no need for large thread pools used in traditional blocking servers. There are no blocking calls to absorb
I write about engineering leadership, productivity, and building high-performing teams. Subscribe for actionable frameworks.
Handling Blocking calls
While blocking calls should be avoided. Reactor provides `publishOn` operator that can be used to send a blocking call to be processed on a separate thread
Mutable states
Reactive streams are constructed as a pipeline of sequence of steps that are executed sequentially. The code in a pipeline is never executed concurrently. No need to worry about mutable states
1.4 When to use Reactive Non Blocking stack
If you have blocking persistence APIs (JPA, JDBC) or networking APIs to use, Spring MVC will be the choice for these type of services. You can however use both Reactor and RxJava to perform blocking calls on separate thread but you would be not utilizing the benefits of non blocking stack
If your application client is non blocking and your database access or services you interact with are non blocking then Reactive programming is an excellent way to go specially if you are receiving high volume of requests per second to your server
1.5 Blocking I/O vs Non Blocking I/O
Frameworks like NodeJs make sure of something called an event loop to gain performance improvements in I/O operations. Event loop is a sort of while(true) loop that continuously checks if there are events ready for processing and then will process them at that time. in case of no events available an event loop will usually block on the call to get events that way it frees the CPU for other work.
Blocking I/O
Traditional blocking servers like tomcat 2.5 and older will have a Thread per request model. When a client makes a request to a server the server handles this request on a thread if this request requires some network communication the thread must block waiting on the response of that network call.
When a new request comes in, the server must create another thread to handle that request. Creation of many threads and context switching between them is expensive and takes time from cpu not doing actual work
Non Blocking I/O
In Non blocking I/O servers the server will have a smaller number of threads handling requests. Requests come on on single thread loop this loops executes the request to the end and handle the next request. When a request coming in involves further network calls the network call will be handled on a separate thread and when the response event is ready the event loop will pick up the event and execute the callback method.
Further reads on the topic available here:
https://medium.com/@FloSloot/node-js-is-not-single-threaded-88928ada5838
https://medium.com/ing-blog/how-does-non-blocking-io-work-under-the-hood-6299d2953c74
2. Basics
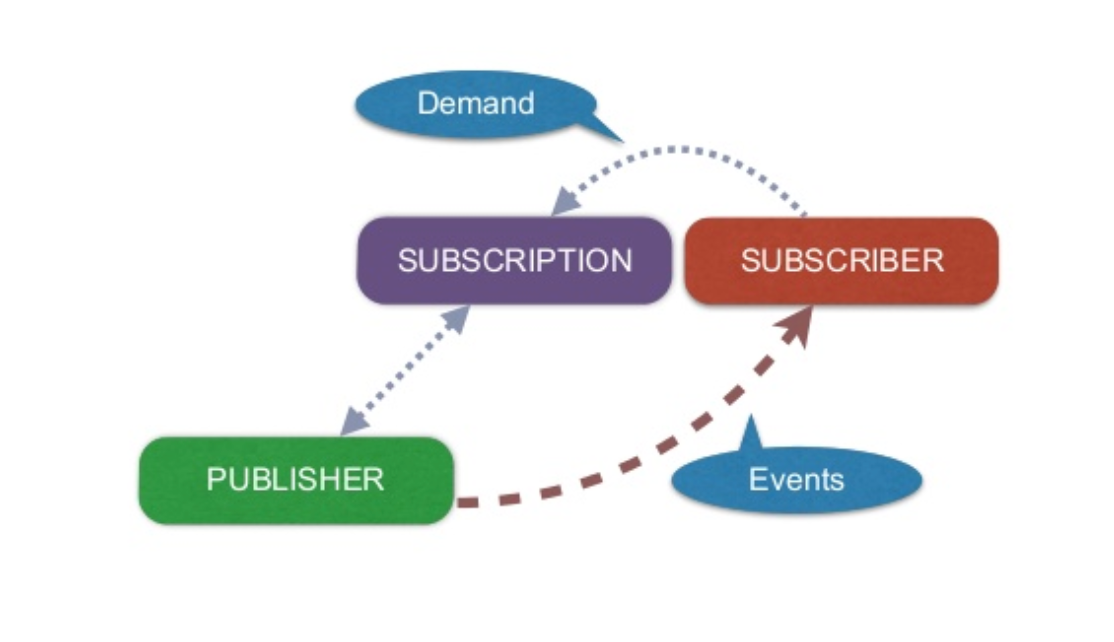
2.1 Subscriber, Publisher and Subscription
Flux.range(1, 5)
.map(i -> {
return i * 10;
})
.filter(i-> i < 10)
.flatMap(i-> dbDao.storeInDB(i))
.subscribe();
}2.2 Nothing happens till Subscription
When A subscriber subscribes to a publisher a single request signal is sent from the subscriber up the chain all the way to publisher, tying this publisher to the subscriber and starting the flow processes. There's one exception to this rule relating to Hot streams read more about that in section 2.4
2.3 BackPressure
This signal process explained in the previous section is used to implement backpressure. A subscriber can work in unbounded mode allowing the publisher to push data in its fastest achievable rate or use request mode that it is ready to process at most N elements. Some operators support prefetching. allowing the source to produce the elements before they are requested if producing the elements is not costly. This is a hybrid Pull-push model allowing downstream to pull n elements if available if not wait to be pushed elements when they are available
2.4 Hot vs Cold streams
Reactor streams can be Hot or Cold, It is important to understand the difference between these types of streams in order to successfully implement applications using streams
Cold streams are lazy streams of data, they don't flow until a subscriber subscribes to them. When you subscribe to them you receive all the data in them. The data emitted by a cold stream is not shared among its subscribers. Cold streams are used to represent asynchronous actions that will not execute until someone is interested in the result. Another example of cold streams is data in a database they are available but wont be fetched and transferred from the database until a subscriber is interested in them. Each time a subscriber subscribes to a cold stream it triggers the source to produce data again, if that source wraps an http call then multiple http calls will be made
Hot streams are streams which produce data whether someone subscribes to them or not. The data is shared between the subscribers. When a subscriber subscribes to a hot stream they will receive data emitted by the hot stream after their subscription they will not receive data previously emitted. Example of Hot streams is a stock ticker or a thermometer readings that are emitted by the thermometer whether someone is interested or not. When you subscribe you get the next reading
Moral of the story, If you are not subscribed to a hot stream you will not receive its data and that data will be lost
Flux.just(httprequest)
Mono.just() and Flux.just() are examples of hot publishers they capture the value at assembly time and replay it to subscribers. Meaning if .just() wrapped an http call, only one call is made and the result is stored and replayed to each subscriber
you can transform just to a cold publisher by using .defer() in this case it is deferred to subscription time and multiple http calls will be made
2.5 Servers
WebFlux relies on Servlet 3.1 non-blocking I/O and uses the Servlet API behind a low-level adapter and not exposed for direct use., In case of Netty it is a non servlet server and its APIs are used directly by the framework
| Server name | Server API used | Reactive Streams support |
|---|---|---|
Netty | Netty API | |
| Tomcat | Servlet 3.1 non-blocking I/O; Tomcat API to read and write ByteBuffers vs byte[] | spring-web: servlet 3.1 non blocking I/O to Reactive Streams bridge |
3. Development APIs
3.1 Mono and Flux
Loading data from the database, manipulate it and then return it to the caller.
In a traditional imperative system, this would be done by retrieving a list, and iterating over it:
List<User> users = userDao.getUsers();
List<String> names = new ArrayList<String>();
for (int i = 0; i < users.size(); ++i) {
names.add(users.get(i).getName());
}In a functional system, where we have a stream of values over a collection, we could instead do this using java8 stream apis:
List<String> names = userDao.getUsers().stream() .map(user -> user.getName()) .collect(Collectors.toList());
Looks simpler but is still a blocking call. Our thread will be blocked waiting for the data to come back before we can do anything with the data.
In a reactive non blocking model, we can do something like this:
Flux<String> names = reactiveUserDao.getUsers() .map(user -> user.getName());
This looks like the functional approach before. However, because this is reactive the entire command is non-blocking so our main thread is not tied up in the operation. Additionally, if the caller is also reactive, then the non-blocking nature propagates all the way.
For example, if this was a reactive web server then the thread handling the request will be immediately free to handle other requests, and as the data appears from the database – it will be sent down to the client automatically. This happens with Spring boot WebFlux application through Netty server
Here's are few more examples
/**
Get upcs for a basket by basket id
*/
@GetMapping("/baskets/{id}/upcs")
public Flux<String> getBasketUpcs(@PathVariable("id") UUID basketId){
}
Mono<Basket> basket = reactiveBasketDao.getBasket("1a2e8a02-add3-40fa-973f-d47b6ee39eee");
Flux<String> basketUpcs = basket.flatMapMany(Basket::upcs);
return basketUpcs;Important methods to know
Mono
Mono.zip(MonoPublisher1, MonoPublisher2) → zips multiple monos together effectively waiting on all of them to respond before it will execute the following code
Mono.just(1) // create a mono of one event of value 1Flux
Flux.map(b-> b.get1()+b.get2()) // code inside map is executed synchronously
Flux.flatMap(b→ Flux.just(1,2,3), concurrency) // code in flatmap is executed asyncronously use for asyncronous operations, by default concurrency set to 256 can be changed, watch out for api calls and db calls when using flatMap!
Flux.concatMap() // similar to flatMap except respects order or operation
Flux.collectList() // return Mono<List<?>>
Flux.collectSet() // return Mono<Set<?>>
Flux.collectMap() // return Mono<Map<?,?>>
Flux.buffer(2100) // grab 2100 elements at most at once, useful for preparedStatement parameters limit for example
Flux.transform() // transform a flux of values to another flux of values, can be used to simplify code
Flux.Just(1,2,3) // create a flux of events of value 1,2,3
Flux.fromIterable() // create a flux from any type implementing Iterable interface, list, set ...
Flux.fromStream() // create a flux from a java8 stream List.stream()
Flux.groupBy(keyExtrator, int prefetch) → USE Integer.MAX_VALUE for prefetch parameter when in doubt, groupy by creates 256 groups at most by default and if you have more groups than that this method will hang without the prefetch parameter3.2 WebClient
Spring WebFlux includes a client to perform HTTP requests with. WebClient has a functional, fluent API based on Reactor, which enables declarative composition of asynchronous logic without the need to deal with threads or concurrency. It is fully non-blocking, see more info in the link below
We utilize webclient to continue the pattern of making functional asynchronous non blocking http requests
We first create a WebClient Bean that will be available for use in our application as follows
@Configuration
public class WebClientConfig {
@Bean
public WebClient webClient () throws SSLException {
} }
SslContext sslContext = SslContextBuilder.forClient()
.trustManager(InsecureTrustManagerFactory.INSTANCE)
.build();
HttpClient httpClient = HttpClient.create().secure(t -> t.sslContext(sslContext));
return WebClient.builder().clientConnector(new ReactorClientHttpConnector(httpClient))
.build();Then Http requests can be done as following
private Mono<Map<Integer, PricingCluster>> getAllClusters () {
String uri = spAdminBaseUrl + GET_ALL_CLUSTER_TYPE_API;
return webClient.get().uri(uri)
}
.retrieve()
.bodyToFlux(PricingCluster.class)
.doOnError(e -> LOGGER.error("Error getting all clusters"))
.doFinally(
x -> LOGGER.info("Finished calling service to get all clusters"))
.collectMap(PricingCluster::getClusterTypeId,
pricingCluster -> pricingCluster);3.3 Schedulers
Schedulers provides various Scheduler flavors usable by publishOn or subscribeOn :
parallel(): Optimized for fastRunnablenon-blocking executionssingle(): Optimized for low-latencyRunnableone-off executionselastic(): Optimized for longer executions, an alternative for blocking tasks where the number of active tasks (and threads) can grow indefinitelyboundedElastic(): Optimized for longer executions, an alternative for blocking tasks where the number of active tasks (and threads) is cappedimmediate(): to immediately run submittedRunnableinstead of scheduling them (somewhat of a no-op or "null object"Scheduler)fromExecutorService(ExecutorService)to create new instances aroundExecutors
subscribeOn means running the initial source emission e.g subscribe(), onSubscribe() and request() on a specified scheduler worker (other thread), and also the same for any subsequent operations like for example onNext/onError/onComplete, map etc and no matter the position of subscribeOn(), this behavior would happen
And if you didn't do any publishOn in the fluent calls then that's it, everything would run on such thread.
But as soon as you call publishOn() let's say in the middle, then any subsequent operator call will be run on the supplied scheduler worker to such publishOn().
here's an example
Consumer<Integer> consumer = s -> System.out.println(s + " : " + Thread.currentThread().getName());
Flux.range(1, 5)
.doOnNext(consumer)
.map(i -> {
System.out.println("Inside map the thread is " + Thread.currentThread().getName());
return i * 10;
})
.publishOn(Schedulers.newElastic("First_PublishOn()_thread"))
.doOnNext(consumer)
.publishOn(Schedulers.newElastic("Second_PublishOn()_thread"))
.doOnNext(consumer)
.subscribeOn(Schedulers.newElastic("subscribeOn_thread"))
.subscribe();The result would be
1 : subscribeOn_thread-4
Inside map the thread is subscribeOn_thread-4
2 : subscribeOn_thread-4
Inside map the thread is subscribeOn_thread-4
10 : First_PublishOn()_thread-6
3 : subscribeOn_thread-4
Inside map the thread is subscribeOn_thread-4
20 : First_PublishOn()_thread-6
4 : subscribeOn_thread-4
10 : Second_PublishOn()_thread-5
30 : First_PublishOn()_thread-6
20 : Second_PublishOn()_thread-5
Inside map the thread is subscribeOn_thread-4
30 : Second_PublishOn()_thread-5
5 : subscribeOn_thread-4
40 : First_PublishOn()_thread-6
Inside map the thread is subscribeOn_thread-4
40 : Second_PublishOn()_thread-5
50 : First_PublishOn()_thread-6
50 : Second_PublishOn()_thread-5
3.4 Techniques
Functional fluent chained method calling is cool and will make you feel like a ninja but keep code simple and readable to avoid angry co workers!!
public Mono<ResponseCampaignModel> getCampaignModel(String id){
return manager.getCampaignById(id)
.flatMap(campaign -> manager.getCartsForCampaign(campaign)
.flatMap(carts -> {
Flux<Product> products = manager.getProducts(campaign);
return products.zipWith(carts, (p, c) -> new CampaignModel(campaign, p, c));
})
.groupBy(model->model.campaign(),Integer.MAX_VALUE)
.flatMap(campainFlux-> campaignFlux.collectList().map(list -> aggregateCampaign(list)))
.flatMap(model -> ImmutableResponseCampainModel.builder()
.campaign(model.campaign())
.products(model.products())
.productsIdentifiers(model.products().stream().map(p->p.getIdentifier()).collect(Collectors.toList()))
.carts(model.carts())
.build()); }See the code above it is just a demonstration of how much chaining can be done and more! all back to back
1- Practice breaking up code into logical reusable chunks and seperate those chunks into separate methods
2- Avoid tight coupling methods that return objects grouping
3- Document, explain, Draw ASCII if you want to help your coworkers follow
3.5 Logging
Use do methods as side effect methods to do your logging and metrics collection or other things you need to do without modifying the flow
Flux.doOnSuccess()
Flux.doOnNext()
Flux.doOnComplete()
Flux.doOnError()
......
4. Reactor Kafka
Coming soon
5. Testing
5.1 StepVerifier
The following code uses StepVerifier library to subscribe to the Mono returned by collecting the flux of basket products and then verifies products list size and that it contains product 12
StepVerifier.create(basketingService.getProducts(basket).collectList())
.expectNextMatches(products -> products.size() == 6 && !products.contains(6)
"12"))
.verifyComplete();
&& products.contains(5.2 Testing failed flux
Handling Checked exceptions in flux
@Test
public void testHandlingCheckedExceptions() {
Flux<String> flux = Flux.just("A", "B", "C")
.log()
.map(element -> {
try {
return generateCheckedException(element);
} catch (IOException e) {
// convert the checked exception to runtime (unchecked exception)
throw Exceptions.propagate(e);
} });
flux.subscribe(
event -> LOG.info("event received {}", event),
error -> {
}
if (Exceptions.unwrap(error) instanceof IOException) {
LOG.error("Something went wrong during I/O operation");
} else {
LOG.error("Something went wrong");
} });
private static String generateCheckedException(String input) throws IOException {
if (input.equals("C")) {
throw new IOException("Failed IO");
}
return input;
}5.3 Testing a flux result of unpredectable order
There are several approaches to dealing with this you can often sort the flux response based on some comparator. alternatively you can use test library that check for list equality ignoring order
6. Debugging
6.1 Blockhound
6.2 Reactor Debug Agents
Honourable Reads
- Reactor Core - https://projectreactor.io/docs/core/release/reference/
- Reactor Error Handling - https://medium.com/@kalpads/error-handling-with-reactive-streams-77b6ec7231ff
- Reactive kafka - https://projectreactor.io/docs/kafka/release/reference/
- Reactive Netty - https://projectreactor.io/docs/netty/release/reference/index.html
- Reactive Scheudling - https://spring.io/blog/2019/12/13/flight-of-the-flux-3-hopping-threads-and-schedulers
- Reactor Testing - https://projectreactor.io/docs/core/release/reference/index.html#testing
- Common Mistakes - https://medium.com/@nikeshshetty/5-common-mistakes-of-webflux-novices-f8eda0cd6291
- Exception Handling - https://medium.com/@knoldus/spring-webflux-error-handling-in-reactive-streams-98b15f7b98b8
If you found this useful, subscribe for more practical engineering leadership content.


