

On this post we discuss what is Cassandra, how to use it, and how to model data appropriately to get good performance and scalability
What is Cassandra
Wide Columnar No SQL database (non relational, no joins support )
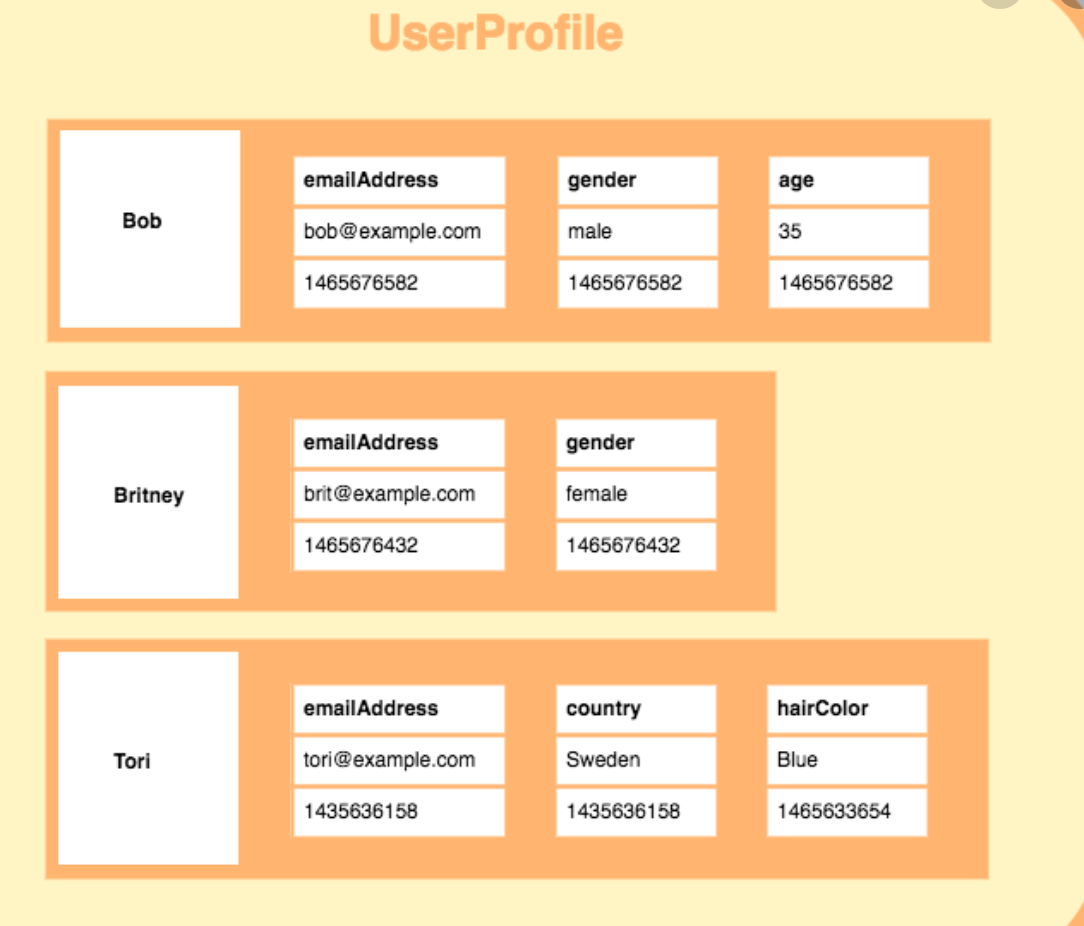
Goals and non Goals in Cassandra
Non-Goals in Cassandra
- Number of writes: writes are cheap in Cassandra very efficient and fast, focus on modeling for better read performance even if it means more writes. Reads are more expensive and are harder to tune for better performance
- Minimize data duplication: Denormalization and data duplication is fact of life with Cassandra. Don’t be afraid to duplicate the data. Disk space is cheapest resource compared to cpu, memory, disk IOPs and network. Cassandra is designed to take advantage of that. There’s no JOINs in Cassandra, they are not efficient anyways in a distributed system
Goals
- Spread the data evenly around the cluster: The key to spreading data evenly around the cluster, is your choice of the partition key, which is the first part of the Primary key. Rows are spread around the cluster based on hash of the partition key.
- Minimize the number of partition reads: When you issue a read query you want to read from as little partitions as possibly. Readings from more partitions cause overhead of the coordinator issuing multiple queries to multiple nodes and and increase variation in latency. Even on single node it is more expensive to read from multiple partitions because of the way the rows are stored
Using One big partition, while solves goal 2 will violate goal 1. You need to find balance between the two. The key is to know your queries before hand and Model around your queries! Try to create a table where you can satisfy your query by reading (roughly) one partition
One table per query pattern. Each table is built to answer a high level query. If you need multiple queries you need different tables. This is how to optimize for reads. Many of the tables may repeat the same data and that’s ok
Modeling Examples
Example 1 User Lookup
we have users and want to look them up
Step 1 - determine which queries to support
- look up user by username get full list of user details
- look up user by email get full list of user details
Step 2 - try to create a table where you can satisfy your query by reading (roughly) one partition
- Since we want to get full details for the user with either look up we need two tables
Good approach (optimized for read queries)
CREATE TABLE users_by_username ( username text PRIMARY KEY, email text, age int )
CREATE TABLE users_by_email ( email text PRIMARY KEY, username text, age int )Bad approach optimized for normalization of data (each read needs two partitions )
CREATE TABLE users ( id uuid PRIMARY KEY, username text, email text, age int )
CREATE TABLE users_by_username ( username text PRIMARY KEY, id uuid )
CREATE TABLE users_by_email ( email text PRIMARY KEY, id uuid )While data is distributed evenly but we have to read two partitions, reads are now twice as expensive
Example 2 User Groups
requirements changed, users are in groups. We want to get all users in a group
Step1 - Specify the queries to support,
- get full user info for every user in a particular group. Order does not matter
Step2: create table to satisfy query by reading roughly one partition.
We can use a Compound Primary Key. This will give one partition per group with records ordered by username
Approach 1
CREATE TABLE groups ( groupname text, username text, email text, age int, PRIMARY KEY (groupname, username) )
SELECT * FROM groups WHERE groupname = ? -- Fetch all info for all users in a user group
IT satisfies goal of reading roughly one partition but not distributed evenly. if we have thousands or millions of small groups with hundred user each it is fine. But if we get one group with million user. The entire burden is shouldered by one node or (set of replicas)
Approach 2
To spread the load more evenly we add another column to the primary key to form a compound partition key
CREATE TABLE groups ( groupname text, username text, email text, age int, hash_prefix int, PRIMARY KEY ((groupname, hash_prefix), username) )Hash could be first byte of the hash(of username) modulo four, so the users in this group can be stored across 4 partitions instead of 1. Data more evenly spread out but we now have to read four times as many partitions.
The two goals conflicting. Need to find balance. If a lot of reads and groups don’t get too large we can do 2 instead of 4 or if you have few reads but groups can get large maybe 4 needs to be 10
Don’t do this to reduce duplication of user info across groups
CREATE TABLE users ( id uuid PRIMARY KEY, username text, email text, age int )
CREATE TABLE groups ( groupname text, user_id uuid, PRIMARY KEY (groupname, user_id) )You will need to read 1001 partitions if you have 1000 users in a group. Its 100x more expensive read but if your reads are infrequent and not need to be efficient but username updates are common maybe the above makes sense. Consider your read and update patterns
Example 3: 10 newest users who joined a group; user group join date
CREATE TABLE group_join_dates ( groupname text, joined timeuuid, username text, email text, age int, PRIMARY KEY (groupname, joined) )Note timeuuid is like timestamp but avoids collisions(duplicates)
Clustering is ordered by ascending by default you can query N newest user above By doing
SELECT * FROM group_join_dates WHERE groupname = ? ORDER BY joined DESC LIMIT ?It is efficient, we are reading a slice of rows from a single partition but instead of using order by which is less efficient, you can reverse clustering order
CREATE TABLE group_join_dates ( groupname text, joined timeuuid, username text, email text, age int, PRIMARY KEY (groupname, joined) ) WITH CLUSTERING ORDER BY (joined DESC)The new more efficient query can be
SELECT * FROM group_join_dates WHERE groupname = ? LIMIT ?Unbalanced partitions can happen here. To solve it we can use this time range because of our knowledge of our query pattern
CREATE TABLE group_join_dates ( groupname text, joined timeuuid, join_date text, username text, email text, age int, PRIMARY KEY ((groupname, join_date), joined) ) WITH CLUSTERING ORDER BY (joined DESC)This will create partition for each day, during lookup we will look at first day then second and so on until we satisfy the limit. to minimize the number of partitions read limit is met. We can adjust the time range so we read one or two partitions.If we get 3 users a day maybe we split by 4 day ranges instead of a single day
Allow Filtering
When used Cassandra will retrieve all rows from table then filter out the ones that don’t have the requested value
If table has 1 million rows and 95% of them have the value this is an efficient query you should use allow filtering
Otherwise if reverse and only 2 rows out of 1 million contain the value. It will load 999,998 rows for no reason. If its an often used query better to add index
Read more about allow filtering here
Secondary Indices
Cassandra's built-in indexes are best on a table having many rows that contain the indexed value. The more unique values that exist in a particular column, the more overhead you will have, on average, to query and maintain the index.
For example, suppose you had a races table with a billion entries for cyclists in hundreds of races and wanted to look up rank by the cyclist. Many cyclists' ranks will share the same column value for race year. The race_year column is a good candidate for an index.
When not to use secondary Index
- On high-cardinality columns for a query of a huge volume of records for a small number of results. See Problems using a high-cardinality column index below.
- The query will incur many seeks for very few results , example looking up songs by writer in a table with billion songs. Use a second table, also not recommended on a boolean column
- In tables that use a counter column.
- On a frequently updated or deleted column. See Problems using an index on a frequently updated or deleted column below.
- Cassandra stores tombstones in index until limit of 100k cells. After 100k queries using the indexed value fails and by default Cassandra keeps tombstones for 10 days
- To look for a row in a large partition unless narrowly queried. See Problems using an index to look for a row in a large partition unless narrowly queried below.
- Query on indexed column in large cluster require response from multiple data partitions. The response will slow down with more machines added to the cluster, avoid performance hit by narrowing search
NOTE: When you query is rejected by Cassandra resist using allow filtering.Think about the data and what you are trying to do you options are
You can change your data model, add an index, use another table, Materialized View, or use ALLOW FILTERING.
Read more about when to use secondary Index here
Materialized View Cassandra 3.0
Allow filtering pulls all records then filter out, while secondary indexes are not ideal on high cardinality columns and the recommended Approach is to denormalize the data in multiple tables and duplicate it which is tedious and you must manually sync and manage those tables
Materialized view provides Automated server-side denormalization no more data duplication manually on client side
CREATE TABLE scores
(
user TEXT,
game TEXT,
year INT,
month INT,
day INT,
score INT,
PRIMARY KEY (user, game, year, month, day)
)
CREATE MATERIALIZED VIEW alltimehigh AS
SELECT user FROM scores
WHERE game IS NOT NULL AND score IS NOT NULL AND user IS NOT NULL AND year IS NOT NULL AND month IS NOT NULL AND day IS NOT NULL
PRIMARY KEY (game, score, user, year, month, day)
WITH CLUSTERING ORDER BY (score desc)
CREATE MATERIALIZED VIEW dailyhigh AS
SELECT user FROM scores
WHERE game IS NOT NULL AND year IS NOT NULL AND month IS NOT NULL AND day IS NOT NULL AND score IS NOT NULL AND user IS NOT NULL
PRIMARY KEY ((game, year, month, day), score, user)
WITH CLUSTERING ORDER BY (score DESC)When not to use Materialized view
- Materialized views do not have the same write performance characteristics that normal table writes have
- If the rows are to be combined before placed in the view, materialized views will not work.
- Low cardinality data will create hotspots around the ring (because in the view they will become big partitions )
Only simple select statements, no where and no order byAvailable now in latest releases
Read more about Materialized Views here https://www.datastax.com/blog/2015/06/new-cassandra-30-materialized-views
Tombstones
Deletes in SQL
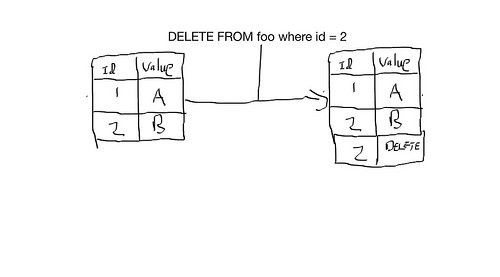
Deletes in Cassandra are actually a marker write
We have to write a marker called tombstone that indicates the record is a delete
There is a time period which defaults to 10 days where 10 days after a delete is issued the tombstone and all records related to that tombstone are removed from the system, this reclaims disk space (the setting is called gc_grace_seconds).
Setting that time less than 10 days can be dangerous in case of network failure the node that is down doesn’t get marked with tombstone and when it comes back up and your other nodes already compacted tombstones the node that was down writes back up the deleted record to others
Other topics to look into not covered in this article
- Collections,
- user-defined types
- static columns can be used to reduce number of partitions needed to satisfy a query
Summary
When to use Cassandra
- Writes exceed reads by a large margin.
- Data is rarely updated and when updates are made they are idempotent.
- Read Access is by a known primary key.
- Data can be partitioned via a key that allows the database to be spread evenly across multiple nodes.
- There is no need for joins or aggregates.
When not to use Cassandra
If you have a database where you depend on any of the following things– Cassandra is wrong for your use case. Please don’t even consider Cassandra. You will be unhappy.
- Tables have multiple access paths. Example: lots of secondary indexes.
- Aggregates: Cassandra does not support aggregates, if you need to do a lot of them, think another database.
- Joins: You many be able to data model yourself out of this one, but take care.
- Locks: Honestly, Cassandra does not support locking. Don’t try to implement them yourself. Many people tried to do locks using Cassandra and the results were not pretty.
- Updates: Cassandra is very good at writes, okay with reads. Updates and deletes are implemented as special cases of writes and that has consequences that are not immediately obvious.
- Transactions: CQL has no begin/commit transaction syntax. If you think you need it then Cassandra is a poor choice for you. Don’t try to simulate it. The results won’t be pretty. There’s batch execute however
Some examples of good use cases for Cassandra are
- Transaction logging: Purchases, test scores, movies watched and movie latest location.
- Storing time series data (as long as you do your own aggregates).
- Tracking pretty much anything including order status, packages etc.
- Storing health tracker data.
- Weather service history.
- Internet of things status and event history.
- Telematics: IOT for cars and trucks.
- Email envelopes—not the contents.
Further Readings
https://towardsdatascience.com/when-to-use-cassandra-and-when-to-steer-clear-72b7f2cede76
https://www.datastax.com/blog/2016/04/cassandra-native-secondary-index-deep-dive
https://www.datastax.com/blog/2016/05/materialized-view-performance-cassandra-3x
http://rustyrazorblade.com/post/2016/2016-02-08-cassandra-secondary-index-preview/
https://www.datastax.com/blog/2014/12/allow-filtering-explained
https://academy.datastax.com/resources/ds220-data-modeling


